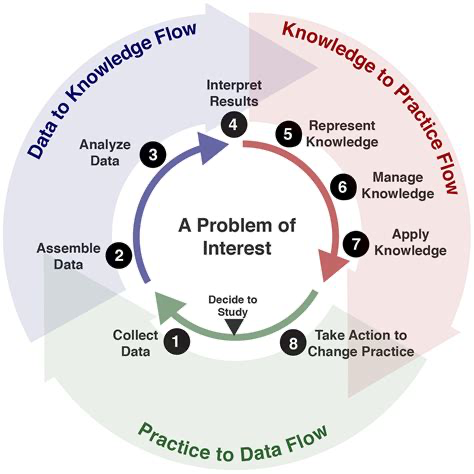
Bringing together data science with improvement science provides a powerful opportunity for creating positive change in education. Both fields have grown rapidly in the past decade, but in education, the two fields have not yet been systematically or consistently combined. In the source article for this blog, Data Intensive Improvement: The Intersection of Data Science and Improvement Science, Krumm and Bowers (2022) discuss opportunities for using intensive data within improvement science approaches in education. The article got us thinking about opportunities for data-intensive improvement within SEERNet.
The SEERNet initiative is opening five large-scale digital learning platforms to external researchers (see the recently released Request for Applications). As the platforms allow comparative studies, one natural paradigm is A/B testing. In A/B testing, an enhanced version of a product feature is tested against the existing version to see which results in greater student learning. Based on Krumm and Bowers’ article, we explore how researchers could also take a broader Improvement Sciences frame. Improvement Science (Bryk et al., 2015) emphasizes identifying an important problem of practice, not simply a possible enhancement to a system–a task that almost always requires involving practitioners.
Improvement Science also takes a systems perspective, meaning that an enhanced design would be enacted not only in the technology, but also in new ways that teachers and students use the technology and engage in activities outside the technology. Improvement Science is iterative, with each cycle opening new questions and gathering new data as the team comes to better understand the problem of interest and the system they are trying to improve. Finally, Improvement Science seeks changes that could be scalable and sustainable in larger populations and this objective often requires moving back and forth between specifics and generalities.
The field of healthcare has effectively brought together improvement science and data science through “learning health systems” (Friedman et al., 2017). Teams working with learning health systems begin with an identified problem of interest. Then they engage in cycles of learning and improvement that work to iteratively transform systems. The first step is to go from “data to knowledge” by gathering complex data about the identified topic (e.g., from electronic health records) along with existing evidence from the literature to learn something useful. Next is going from “knowledge to performance” by taking that new learning and using it to inform changes to local systems and processes. Finally, the process moves from “performance to data” by using those revised systems to generate new data that elucidate whether the implemented changes led to desired outcomes and inform further refinements to the system. Repeated cycles of this system help to accumulate substantial improvements to health systems and practices.
This model for combining intensive data with improvement science can be valuable for education in general and for the SEERNet initiative in particular. There are three specific ways that large, complex data sources can support improvement projects in education: 1) as “boundary objects”; 2) as resources for “zooming in and out” on systems; and 3) as fodder for predictive models to support teaching and learning. Let’s explore each in turn.
Boundary objects are resources or artifacts that people from different communities of practice can use to anchor their joint conversations and collaborative work (Krumm et al., 2021; Liu et al., 2018; Zheng et al., 2019). In education, intensive data serve as a boundary object for researchers and practitioners, providing a common point of reference for folks coming from different organizational and professional backgrounds. The data also serve as a “motivator” for the collaboration because researchers and practitioners together have the combination of contextual knowledge and analytic skills required to make sense of the data, where either group alone does not. Design workshops and data dives are examples of shorter-term engagements where people from different institutions and roles come together to examine data as they kick-off their improvement work. Data-intensive Research Practice Partnerships are an example of longer-term collaborations where teams jointly engage with data to improve education.
In SEERNet, some platforms are offering access to intensive data from the get-go. For example, researchers and practitioners working with Arizona State University (ASU) can use the ASU Learning @ Scale network to explore student profiles, system use, and course performance data from more than 100,000 students across the university system. Researchers and practitioners may want to plan an initial exploratory phase where they examine systems data to identify a pressing problem of practice and define what meaningful “improvement” looks like, before delving into designing solutions. During this phase, teams are encouraged to identify discrepancies in the use-patterns, experiences and/or outcomes of particular groups of students, to inform the improved design.
Zooming in and out refers to analytic processes that mine data to illuminate both broad processes and patterns (zooming out) and also specific examples of a phenomenon (zooming in). The structure and format of intensive data sets are particularly conducive to this type of analytic task. For example, in the case of data from a digital learning environment, a student’s action is typically logged as an event (like starting a new activity in a digital environment) that can be readily combined with data that characterizes that event (like the content students are working on, the teacher or classroom they are in, and the school they attend). Research and design teams have leveraged data from these digital learning environments to identify weaknesses in the original system design and make improvements accordingly. In many cases, subsequent research has shown that students learned better with the updated version of the system than with the original (e.g., Koedinger et al., 2013).
In SEERNet, zooming in and zooming out could involve focusing on a specific population of interest and then also considering broader populations that may benefit from your improvement. For example, using the OpenStax Kinetic platform, teams could zoom in to examine a particular study practice within a specific textbook, and then zoom out to explore the contexts and circumstances across the 6.5 million students within the system where that practice could be effective. Teams can also zoom out to understand how a particular textbook or practice is functioning overall and then zooming in to explore how that textbook or practice is working for a particular population, with the goal of identifying and remedying any opportunity gaps.
Data-intensive systems generate data that can be used to create powerful predictive models to support teaching and learning. Programmers can create models that take the data generated from data-intensive systems and apply rules about specific variables and thresholds to produce instructional guidance for teachers and/or user-facing actions such as recommendations, alerts and visualizations. Many digital learning environments, including online courses and massively open online courses (MOOCs), make use of predictive models to identify and intervene with students who need support. For example, models can identify and support students who are at risk for course drop-out, seeking instructional support, off-task, or even frustrated. Specific considerations are especially important in creating and using predictive models because they employ algorithms that often inadvertently reproduce existing systemic challenges. The potential of predictive models for reducing such challenges to specific populations often lies in identifying students for extra supports or opportunities who may have otherwise fallen through the cracks.
In an example from a SEERNet partner, a team of researchers and practitioners used data from the Assistments intelligent tutoring program to co-design an early warning system for guidance counselors (Ocumpaugh et al., 2017). The team used data about student knowledge and behaviors–including behaviors reflecting engaged concentration, boredom and confusion–to predict standardized test performance and college attendance. They designed customized reports to provide guidance counselors with actionable information. The guidance counselors involved in the co-design pushed the team to ensure that the reports framed predictions for individual students as identifying opportunities rather than creating static and potentially detrimental labels.
Leveraging intensive data for use within improvement projects has great potential. Data from digital environments have already helped a growing number of improvement projects–as boundary objects for bringing different groups together, as a mechanism for providing new vantage points on a system, and through predictive modeling. We are excited to see how people will leverage SEERNet for data-intensive improvement within education.
Bryk, A. S., Gomez, L. M., Grunow, A., & LeMahieu, P. G. (2015). Learning to improve: How America’s schools can get better at getting better. Harvard Education Press.
Friedman, C. P., Rubin, J. C., & Sullivan, K. J. (2017). Toward an information infrastructure for global health improvement. Yearbook of Medical Informatics, 26(1), 16–23. https://doi.org/10.15265/IY-2017-004
Koedinger, K. R., Stamper, J. C., McLaughlin, E. A., & Nixon, T. (2013). Using data-driven discovery of better student models to improve student learning. In Proceedings of the 16th international conference on artificial intelligence in education (pp. 421–430). Springer.
Krumm, A. E., Boyce, J., & Everson, H. T. (2021). A collaborative approach to sharing learner event data. Journal of Learning Analytics, 8(2), 73–82. https://doi.org/10.18608/jla.2021.7375
Krumm, A. E., & Bowers, A. J. (2022). Data-intensive improvement: The intersection of data science and improvement science. Handbook on Improvement Focused Educational Research. Lanham, MD: Rowman & Littlefield.
Liu, R., Stamper, J. C., & Davenport, J. (2018). A novel method for the in-depth multimodal analysis of student learning trajectories in intelligent tutoring systems. Journal of Learning Analytics, 5(1). https://doi .org/10.18608/jla.2018.51.4
Ocumpaugh, J., Baker, R. S., San Pedro, M. O., Hawn, M. A., Heffernan, C., Heffernan, N., & Slater, S. A. (2017, March). Guidance counselor reports of the ASSISTments college prediction model (ACPM). In Proceedings of the Seventh International Learning Analytics & Knowledge Conference (pp. 479-488).Zheng, G., Fancsali, S. E., Ritter, S., & Berman, S. (2019). Using instruction-embedded formative assessment to predict state summative test scores and achievement levels in mathematics. Journal of Learning Analytics, 6(2). https://doi.org/10.18608/jla.2019.62.11
This project is supported by the Institute of Education Sciences, U.S. Department of Education, through Grant R305N210034 to Digital Promise. The opinions expressed are those of the authors and do not represent views of the Institute or the U.S. Department of Education.